
Misbehaving Agents & The Impacts of Extreme Instability
As agents proliferate in number and take on more consequential and complex tasks, we should check if they are behaving consistently.


One month ago we shared Stability Arena - a dashboard that tracks a new metric especially designed for LLMs hosted behind APIs, behavioral stability, which is measured by generating recurring behavioral fingerprints and analyzing how they change over time. We need new metrics beyond uptime and speed to determine if our AI agent-dependent systems are functioning. One question we’ve been exploring is
Is instability why my agent tool calling patterns are changing?
We now have the first glimpses at the impact of instability when agents access models through different hosts.
⚠️ Model endpoints with extreme levels of behavioral instability show high levels of task instability compared to peer endpoints serving the same nominal model.
What is Task Instability?
We use agents (through harnesses like OpenClaw, Claude Code, Codex, Hermes, etc) to do tasks. Ideally we can delegate mundane, repetitive tasks to AI to do on our behalf. For tasks that are going to be done repeatedly, we wanted to know how often the AI model changes how it completes the task, since it is taking ownership of the task and the user is not specifying the individual steps. The agent decides which tools to use and what to do with their outputs. The user just wants to review the final product (or sometimes not even that).
It is important to know how often the agent changes which tools to use when given the same prompt. When the agent chooses a tool or decides it does not need a tool in one run, but changes its mind in the next run, this is a sign of task instability. The more task instability, the more likely the output of the task (or the sequence of tasks) will vary over time.
To simulate task instability we prompt an endpoint to answer “Yes/No” to whether it needs to consult an external reference (in analogy to calling a tool) to answer a question. We repeat the same prompt, always with temperature=0, on a recurring basis and record the endpoint’s Yes/No responses.
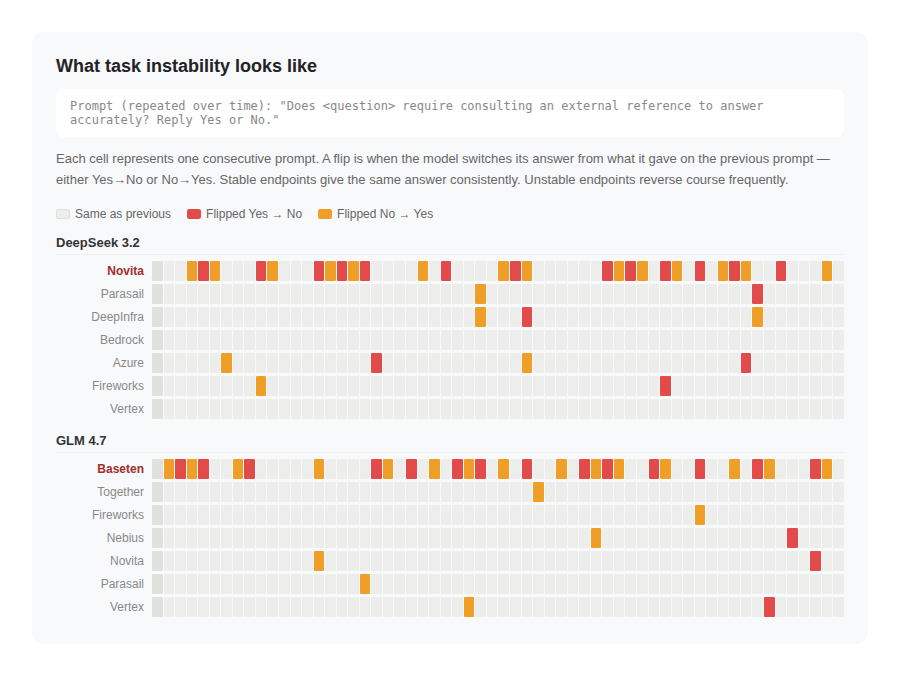
We can quantify the instability of this task simulation by various metrics that capture the extent to which binary “Yes/No” responses vary over time for the same prompt. For example, one such metric is flip rate (illustrated above), which is the proportion of time an endpoint flipped its answer on consecutive prompts. As an aside, the fact that the outputs to the same prompt varied at all at temperature zero should give one pause.
Fingerprint vs Task Instability
Using fingerprint data from Stability Arena, we selected specific endpoints that were showing outlier levels of behavioral instability relative to peers hosting the same nominal model. This enabled a natural study where we could analyze task instability on a cohort of providers containing one endpoint with extreme behavioral instability.
While Stability Arena continued to collect fingerprint data, we ran our task instability simulation as an independent process on two of these cohorts.
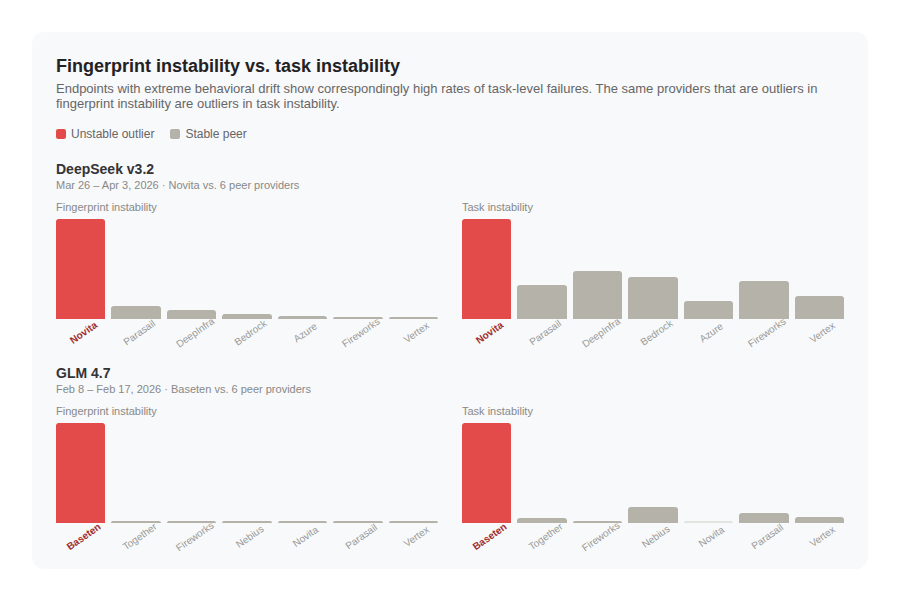
The data clearly shows higher levels of task instability when fingerprint instability is extreme (2+ standard deviations above the norm). In these conditions, the instability of the model endpoint contributes to the task instability.
Warning Signs?
The conditions for this study were fortunate for a few reasons: we had two endpoints that exhibited extreme behaviors relative to a sufficiently large set of peers. And these are naturally occurring since we do not control the endpoints - we are accessing the APIs as any other agent would.
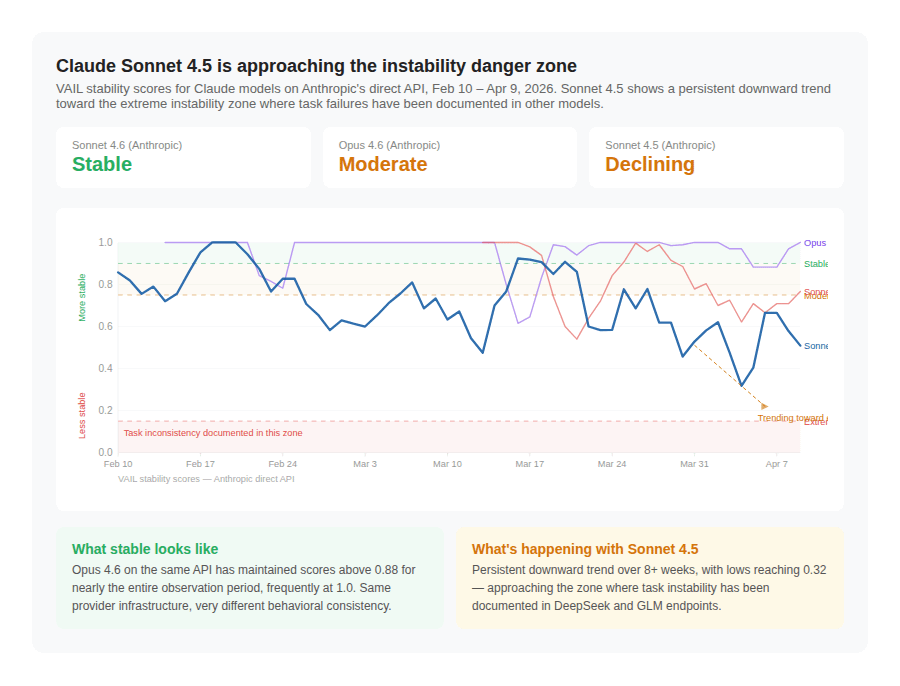
There are other endpoints under similar amounts of stress that we could not include in our study. For example, Anthropic’s APIs have been showing high levels of instability in the last month. We can’t quite say that agentic workflows relying on these APIs are going to break, but it is something to watch out for.
We are delegating more workloads to AI agents, which can be liberating and powerful. However, it’s important we pay attention to these underlying issues that may create more work for us in the aftermath. It is a challenge to predict or eliminate instability from models, regardless of where they are hosted.