
Reliability ≠ Stability
We shouldn't assume reliable model APIs mean we are getting intelligent outputs.

“This model is doing well on public benchmarks, #1 on SWE Bench! We’ve run our internal evals and it performs great! Our inference provider is showing great uptime and super fast TTFT and TPS. We red-team’d it in our app and it passes with flying colors.…SHIP IT LFG 🎉”
Weeks later…
“Wait, what?!? Why is it doing that? Did we change our prompts or something? Why is it not working like it was? Did the model just get dumber out of nowhere?”
Every application builder, product manager, developer, and machine learning engineer can relate to this story. This is the new reality of the software development lifecycle for AI-native applications.
Before AI-native applications, software was deterministic, the same input will result in the same output. We really only needed to check the basics:
Is it up and running?
Is it responding quickly?
Can it handle the throughput?
These are normally reported as standard metrics for any REST API service. They are primarily managed by Site Reliability Engineers (SREs) and easy to setup in standard tools like PageDuty or UptimeRobot.
The reality with AI-native applications is: Reliability ≠ Stability
There is more nuance with AI-native applications. What those developers above are feeling is the instability of the model, even though the metrics show everything is running fine. It is producing tokens, fast, and as many as requested.
However, just because an AI is generating tokens reliably, it does not mean those tokens are the right ones for the application. And it does not mean the tokens it produced for an input a few weeks ago will be the same tokens produced for the same inputs today. AI systems are stochastic machines - meaning the tokens generated at any time are not guaranteed to be the same. This leads to models behaving differently at different times.
When models have varying behavior, it means applications will have varying behavior.
We need a new metric - Stability
Tracking stability is about tracking if an AI model is behaving consistently over time. Stability is about making sure the answers coming back from an AI model are consistent when prompted with the same inputs. Even though we can’t expect the same inputs to give identical responses each time, we should have confidence that the responses are in an expected range. If it starts to veer off or drift (even slightly), this can cause problems in applications where even minor changes in outputs can cause compounding or cascading problems.
Imagine an agent that is relying on a model to perform a complex task that requires many steps in a sequence. If the results of earlier steps are different, then everything to follow can be thrown off.
Currently we rely on model API providers (inference providers) to share their reliability metrics like time-to-first-token (TTFT), tokens per second (TPS), and uptime. However this is no longer sufficient for AI-native applications.

There needs to be a new metric that captures how consistent are the models behaving over time, especially when hosted in different environments.
Shifting Sands

Hosting frontier AI models is no small task. With hundreds of billions or even trillions of parameters, these models require complex compute environments. And as new models come out (with advanced capabilities) with new architectures, inference providers have to update their infrastructure to support them. Additionally, they need to implement their own set of optimizations to get most they can from the hardware they currently have.
Inference providers then are naturally updating their infrastructure, adjusting models, reconfiguring routing, and more all the time.
And as different inference providers make different choices, it leads to models behaving differently.
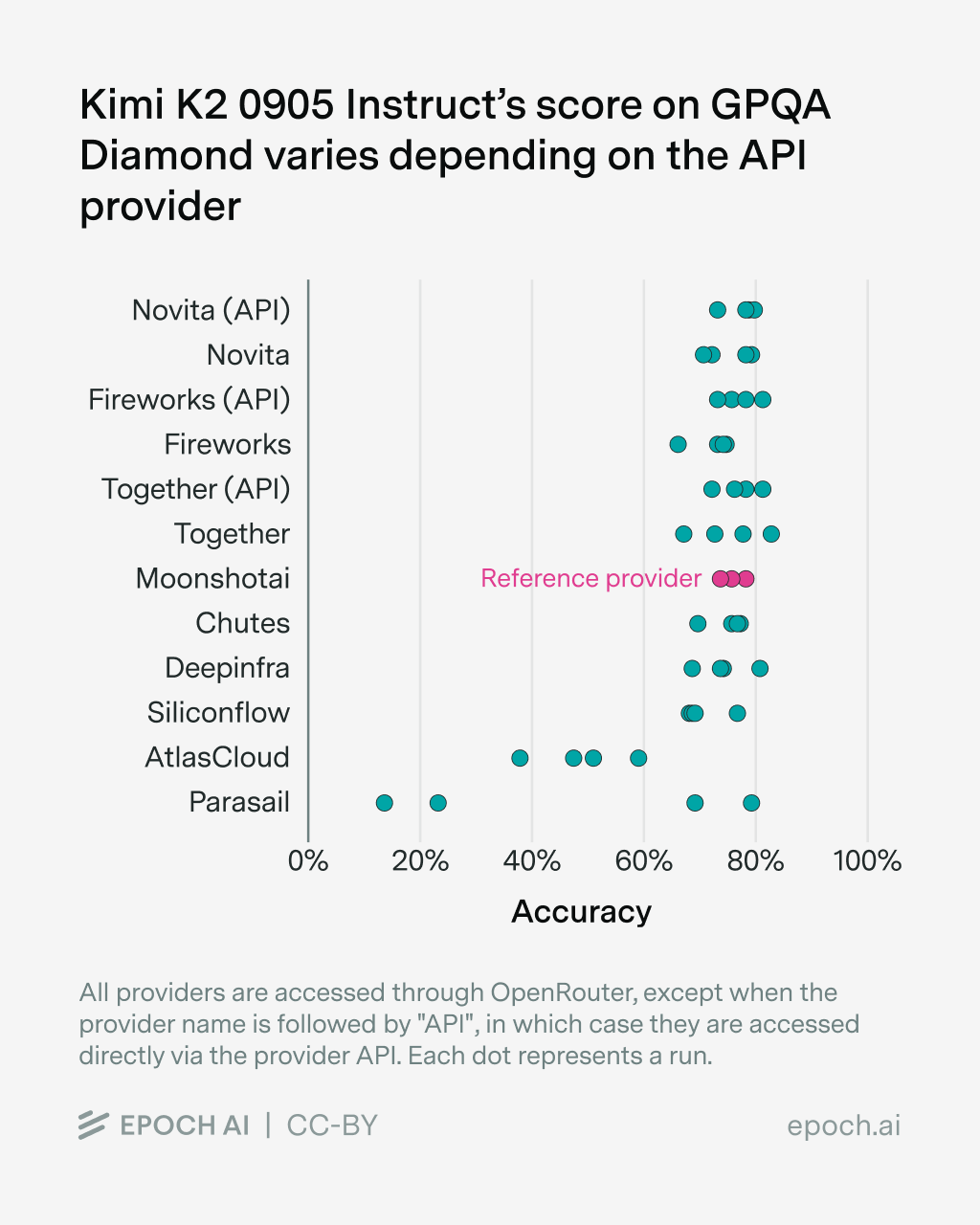
Through our model informatics work, we’ve been able to develop methods to continuously monitor AI models through APIs from different inference providers to track instability. The results were shocking to see. The same model hosted by different providers showed significant variance between them.
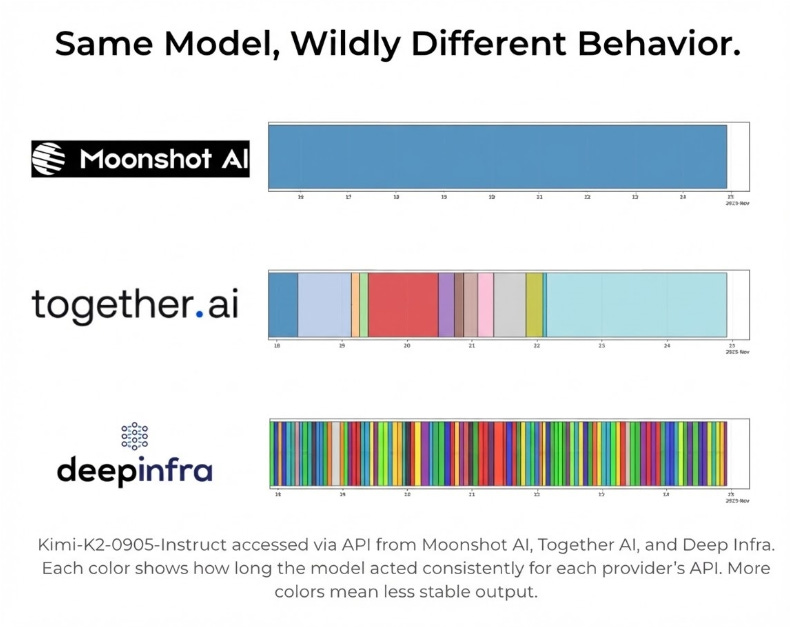
Recently, Epoch AI published results from an independent study and arrived at similar conclusions.
“Bugs and instabilities in the chosen API provider are the biggest source of evaluation errors, which particularly affects newer models.”
Stability Monitoring
The key challenge is that model behavior can be affected by a wide variety of changes to both the model files (weights, tokenizer, etc) as well as the in deployment infrastructure. And those changes happen often and at unpredictable times:
…when we switched hardware providers one of the physical nodes went down and then we had to get another set because it’s a HUGE model.
It means we can’t run checks once a month or even once a week to see if the model our application depends on is behaving the way we need. And it would be too costly to run heavy evals at a high enough frequency.
To do this well, we need a lightweight approach that can run at high frequency and with enough sensitivity to know when the model is not behaving, even when the API is live and responding.
We are excited to share more soon about how we’ve built a stability monitor to detect when model behavior is changing and how it may impact your AI-native applications.